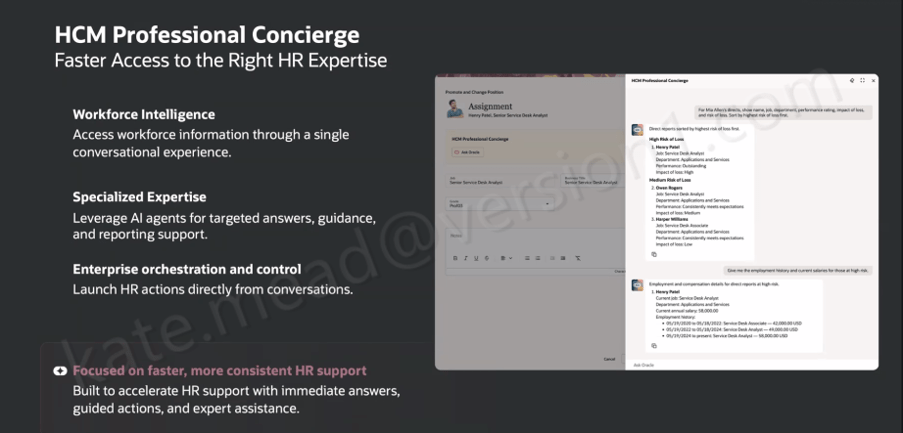
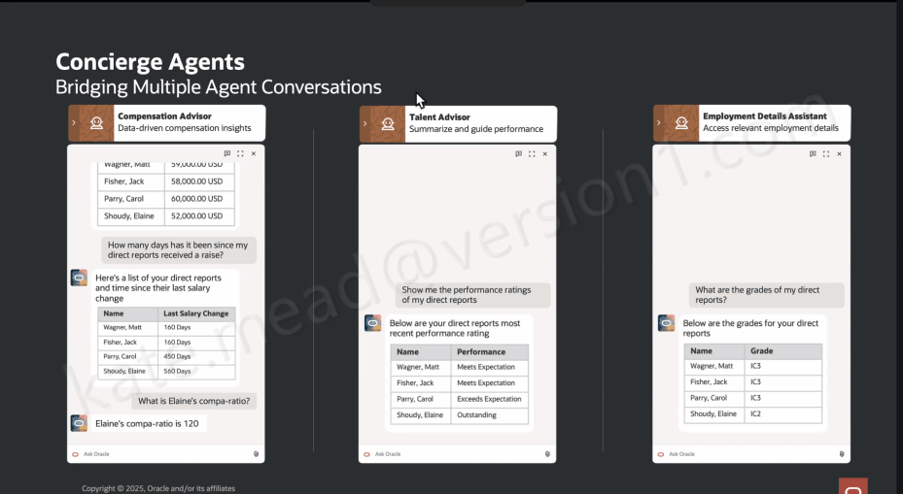
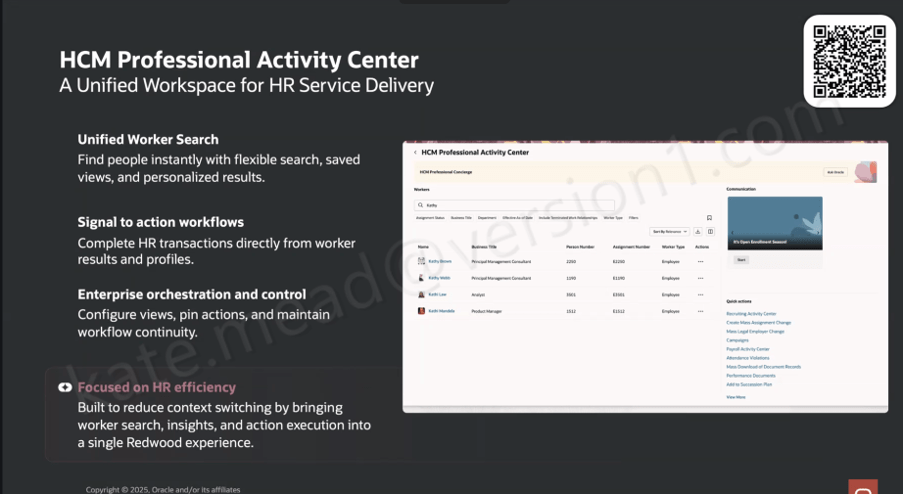
I’ve written about Oracle’s Agentic Applications a few times now, covering the original announcement, the HCM workspaces and, more recently, my hands-on experience with the Agentic App Builder. Every time I think I’ve reached the end of the story, Oracle introduces something new.
This time, rather than looking at individual features, I want to focus on the bigger picture. What is Oracle actually trying to achieve with Agentic Apps, and why should Fusion customers be paying attention? Because what we’re seeing isn’t just another set of AI features. It’s a shift in how enterprise applications are designed to support work.
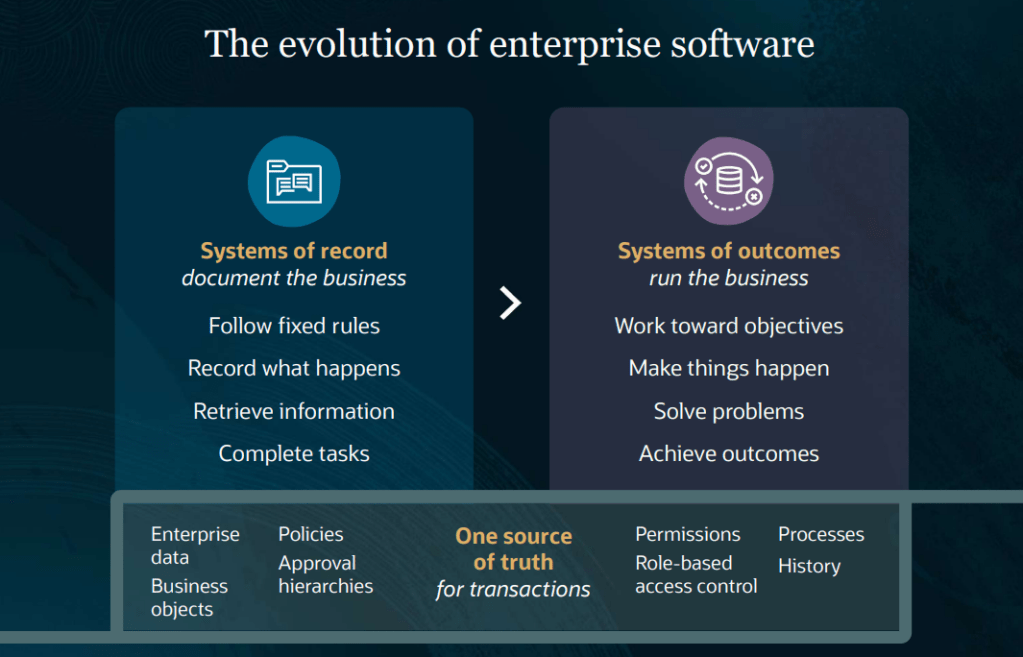
For years, ERP and HCM systems have been systems of record. They capture transactions, store data and provide the processes organisations need to run their business. Employees perform tasks and the system records the outcome.
Agentic Applications introduce a different approach. Rather than simply waiting for users to initiate work, the application continuously analyses data, identifies priorities, recommends actions and, where appropriate, helps execute tasks within existing security and governance frameworks.
The result is a move from recording activity to driving outcomes. That’s a significant change.
Employees aren’t removed from the process. In fact, judgement, approval and decision-making remain firmly in human hands. What changes is the amount of manual effort required to gather information, identify next steps and coordinate routine activities.
Oracle describes this as moving from systems of record to systems of outcomes, and the more I see of the strategy, the more that description feels accurate.
One thing that often gets lost in conversations about AI is that not all AI capabilities are the same. Oracle’s approach now spans four distinct layers.
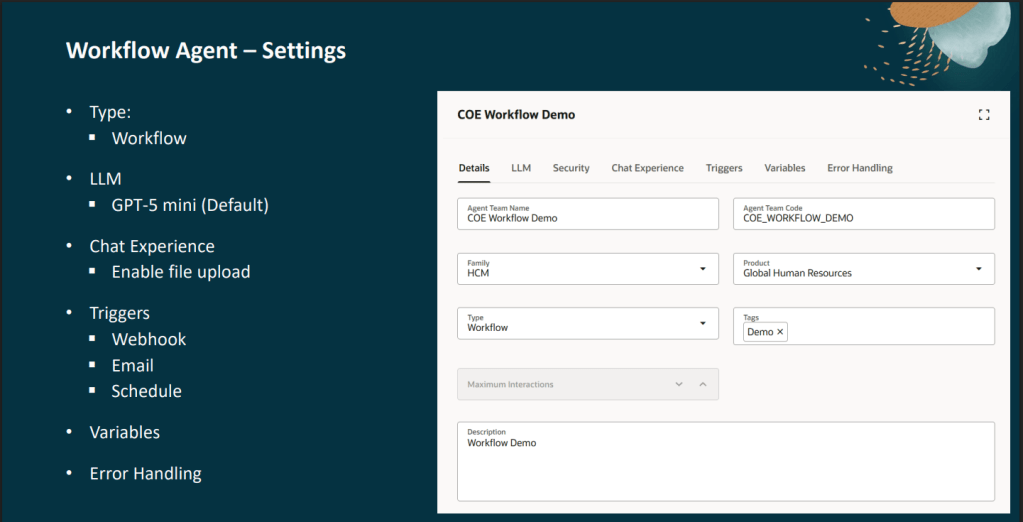
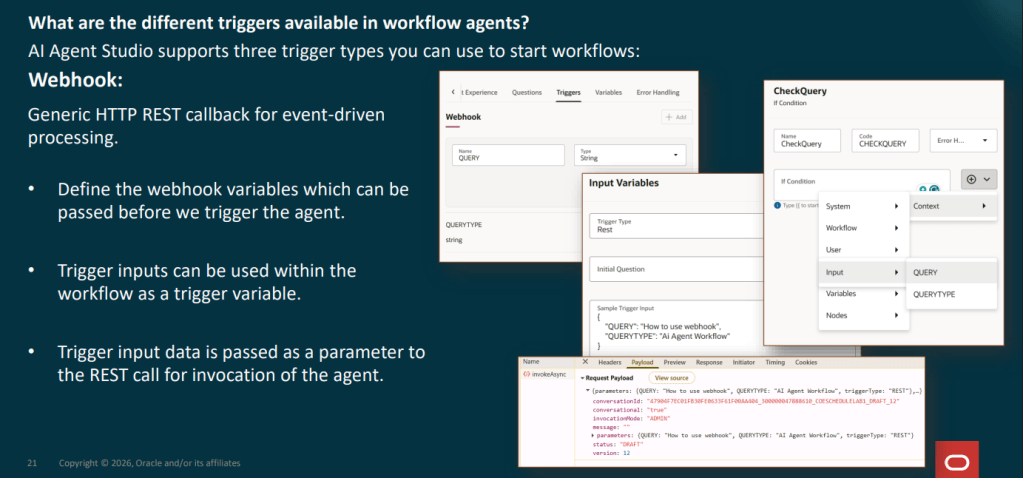
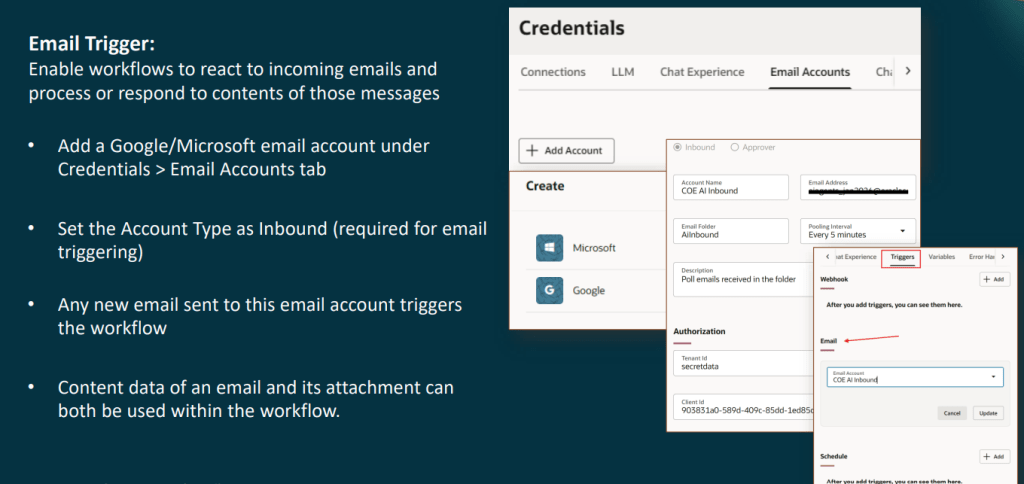
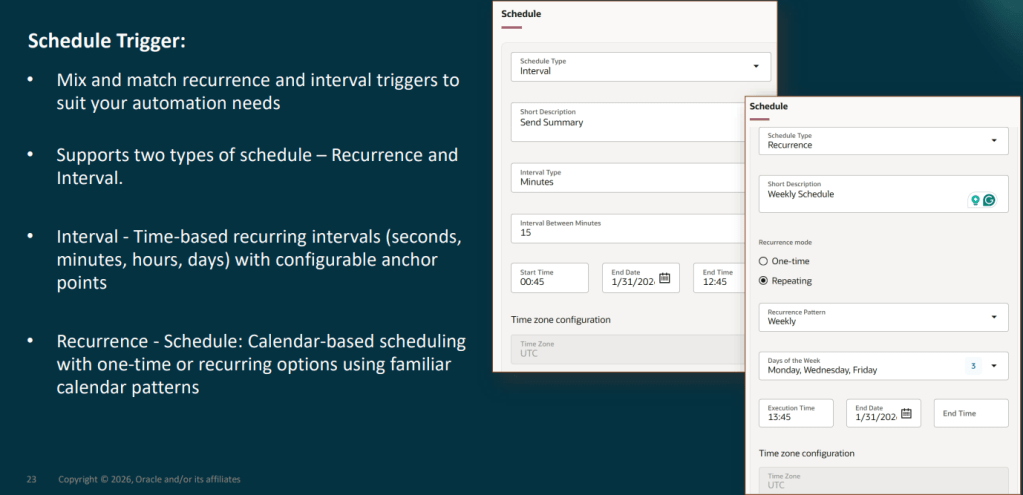
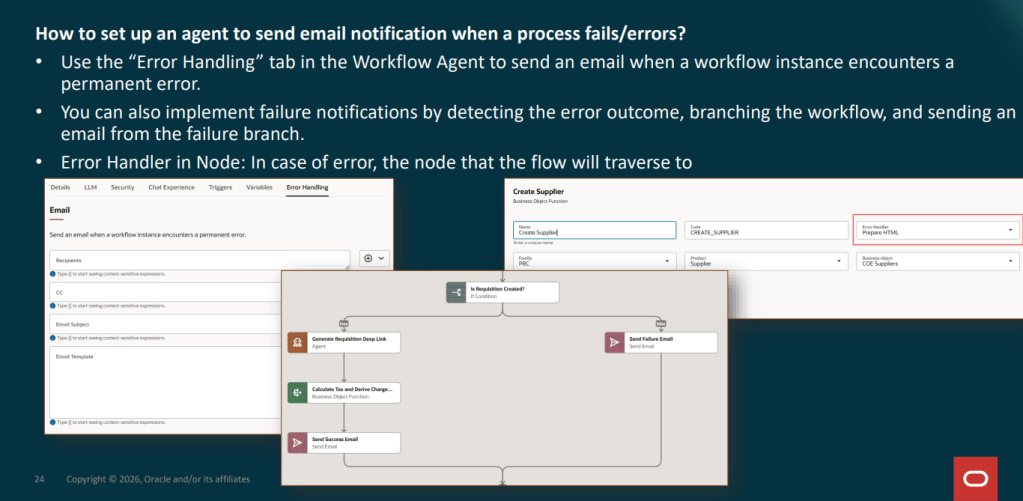
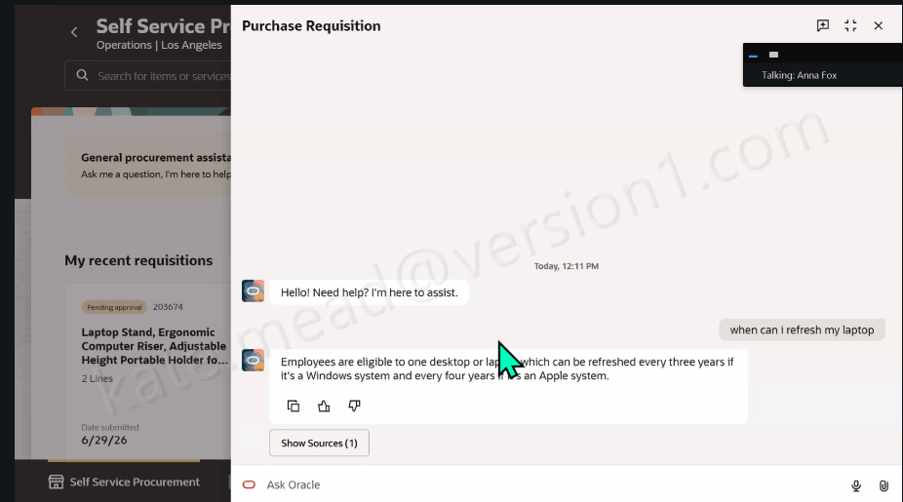
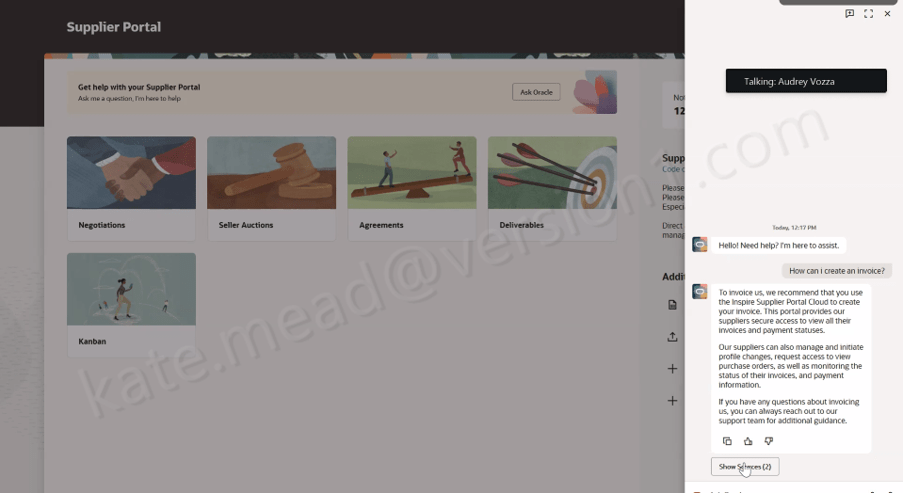
At the most familiar level are generative AI features embedded directly within Fusion user experiences, helping users generate content, summaries and recommendations. The next layer introduces Answer Agents, which provide contextual information and guidance within the flow of work. Beyond that are Workflow Agents that can execute multi-step business processes on behalf of users.
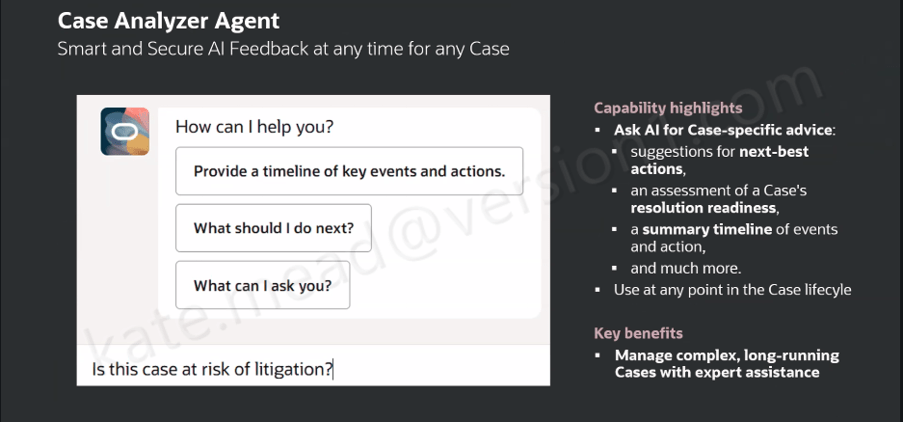
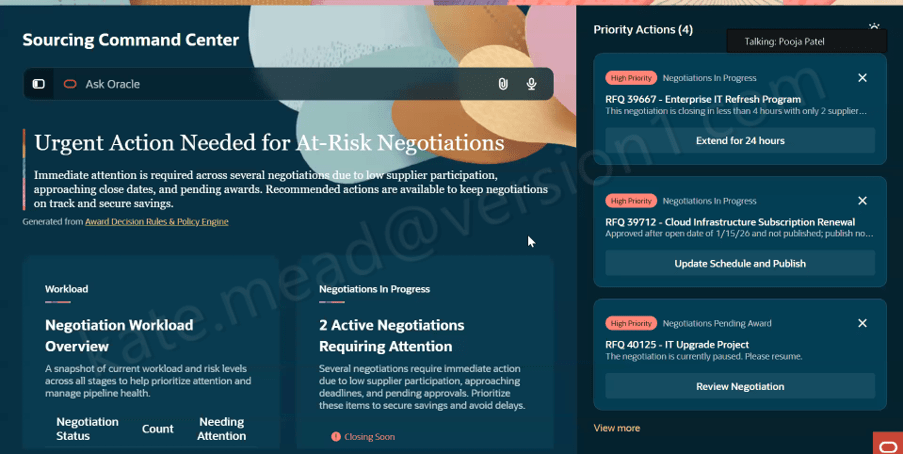
Finally, Oracle has introduced Agentic Applications. These are goal-driven workspaces that coordinate multiple agents and business processes to achieve a specific outcome. The 22 workspaces announced across HCM, ERP, SCM and CX sit firmly within this final category.
For customers starting their AI journey, understanding these layers is important. Not every use case requires a fully agentic application, but they do provide a glimpse of where enterprise software is heading.
Alongside the growing catalogue of pre-built applications, Oracle has continued to invest in the tooling behind them. One of the most important additions is contextual memory, allowing agents to retain relevant information across interactions rather than treating every conversation as a completely new request.
Content Intelligence is another significant development. It enables agents to combine transactional data with enterprise content such as policies, procedures and knowledge articles. This creates opportunities for more sophisticated use cases in areas such as compliance, onboarding and employee support.
Oracle has also expanded support for multimodal interactions, enabling agents to work with information beyond text, including images and voice-based inputs.
For organisations looking at AI as part of a broader technology landscape, Oracle’s support for industry standards such as the Model Context Protocol (MCP) is particularly interesting. It opens the door for Fusion agents to work alongside agents and services running on other platforms, helping organisations avoid creating isolated AI ecosystems.
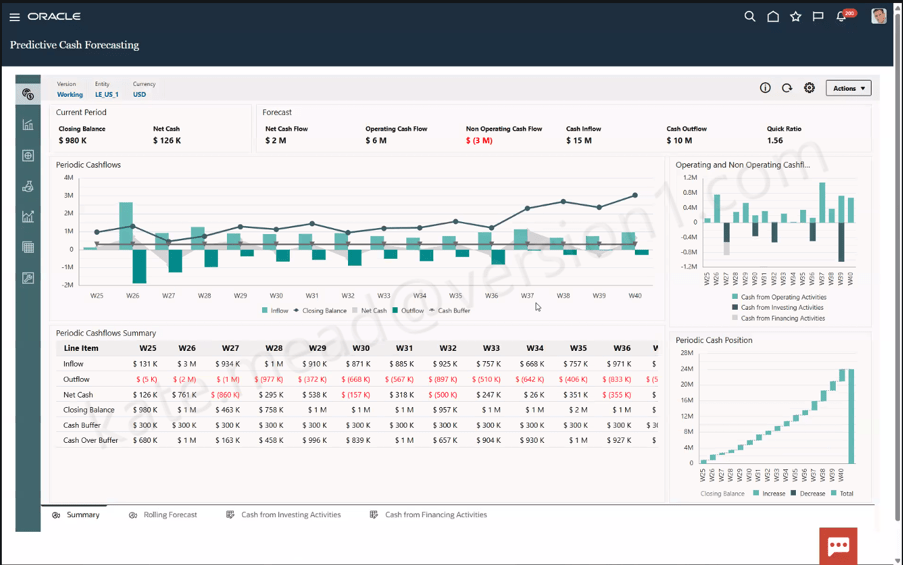
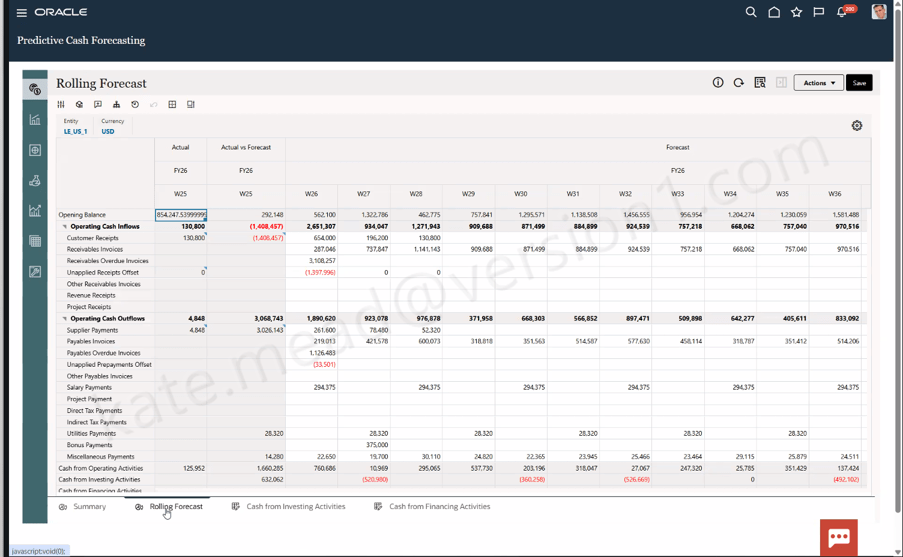
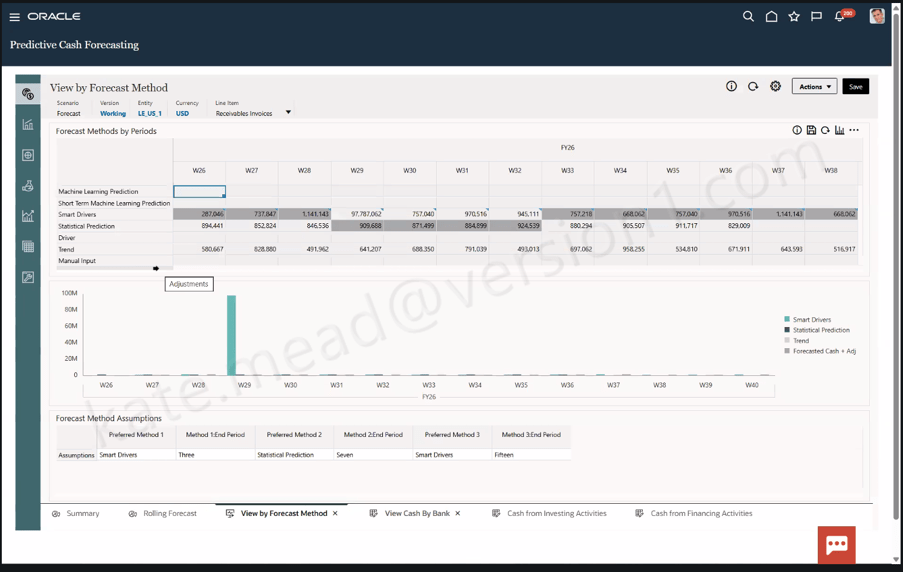
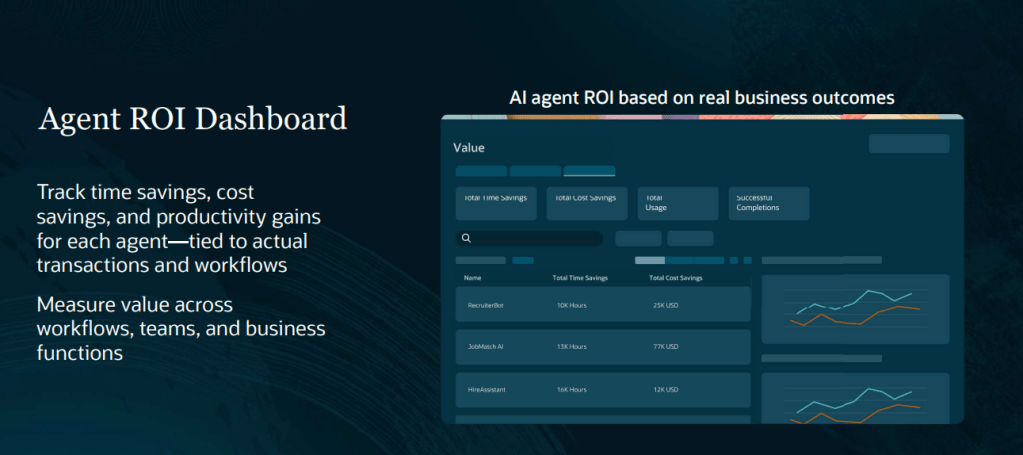
One challenge every AI programme faces is proving value. Organisations understandably want to move beyond demonstrations and understand whether AI is delivering measurable business benefits. Oracle’s new Agent ROI Dashboard aims to address this. The dashboard tracks metrics such as usage, successful completions, time savings and cost savings, giving organisations a way to monitor the impact of individual agents over time.
While the methodology behind any ROI calculation should always be considered carefully, the availability of these metrics provides a practical starting point for conversations with project sponsors and steering committees. Instead of discussing potential benefits in theory, organisations can begin measuring outcomes based on actual usage patterns.
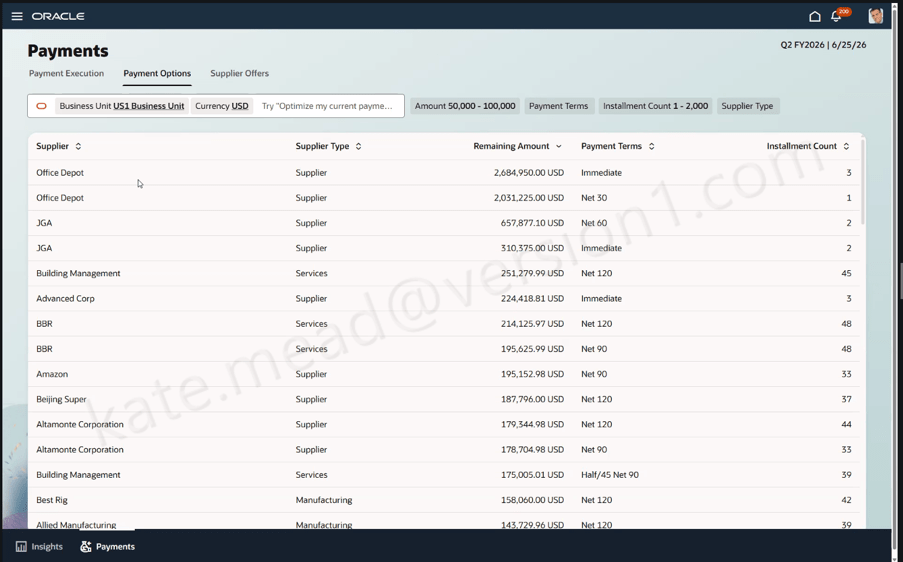
The HCM workspaces have received a lot of attention since their launch, but some of the ERP and SCM use cases are equally compelling.
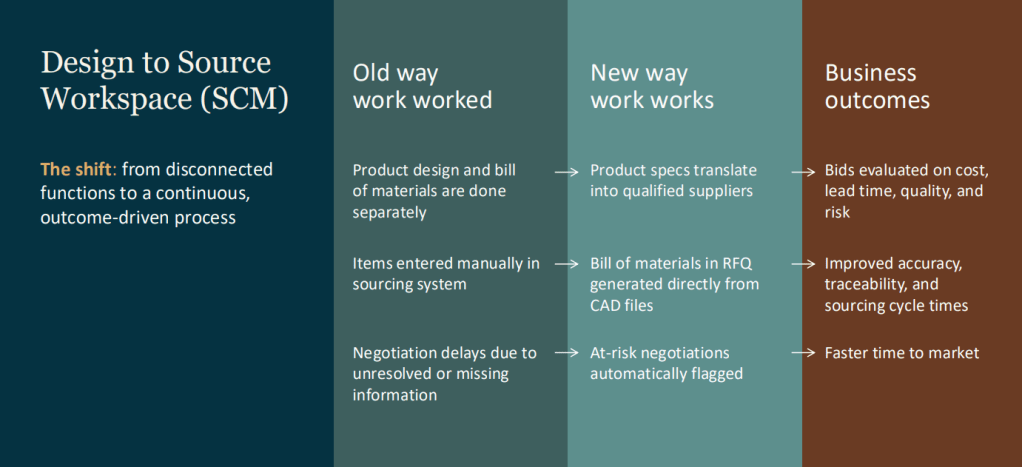
One example is the Design-to-Source Workspace. Traditionally, moving from product design to sourcing can involve multiple teams, disconnected systems and significant manual effort. The workspace connects these activities, helping organisations move more efficiently from bill of materials creation through to supplier engagement and sourcing decisions. What’s particularly interesting is that the workspace doesn’t simply display information. It continuously monitors progress, identifies risks and highlights areas requiring attention.
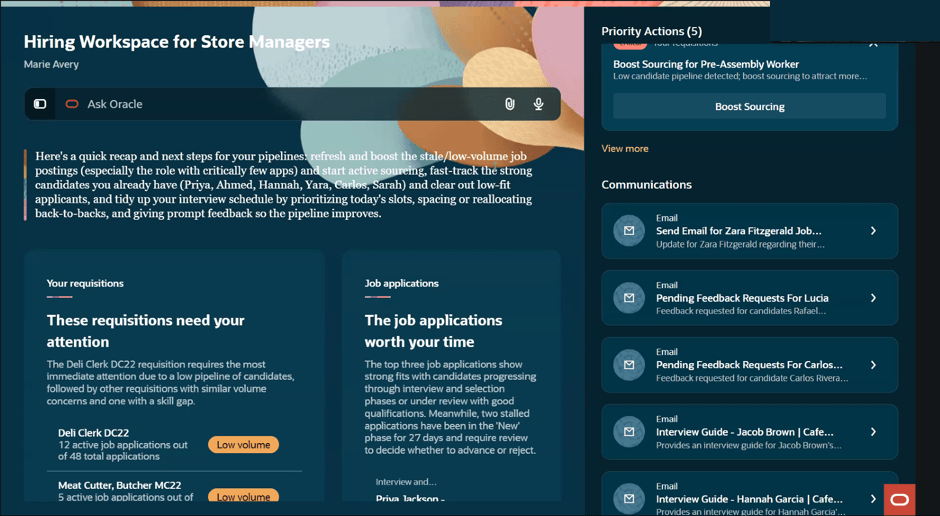
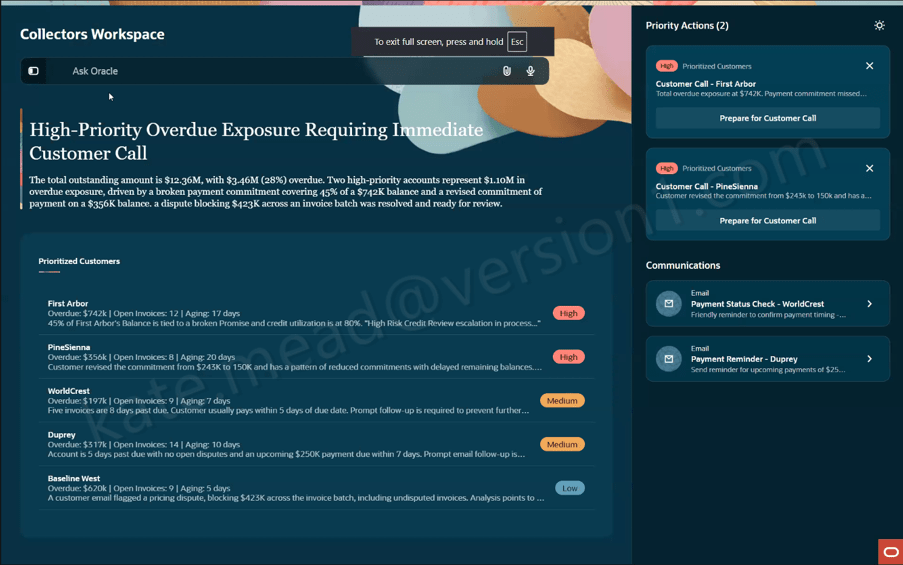
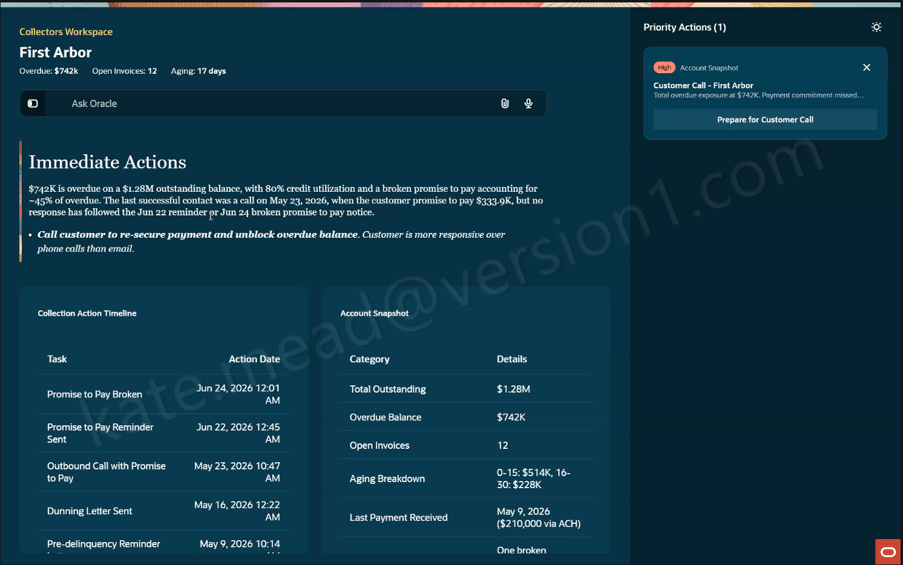
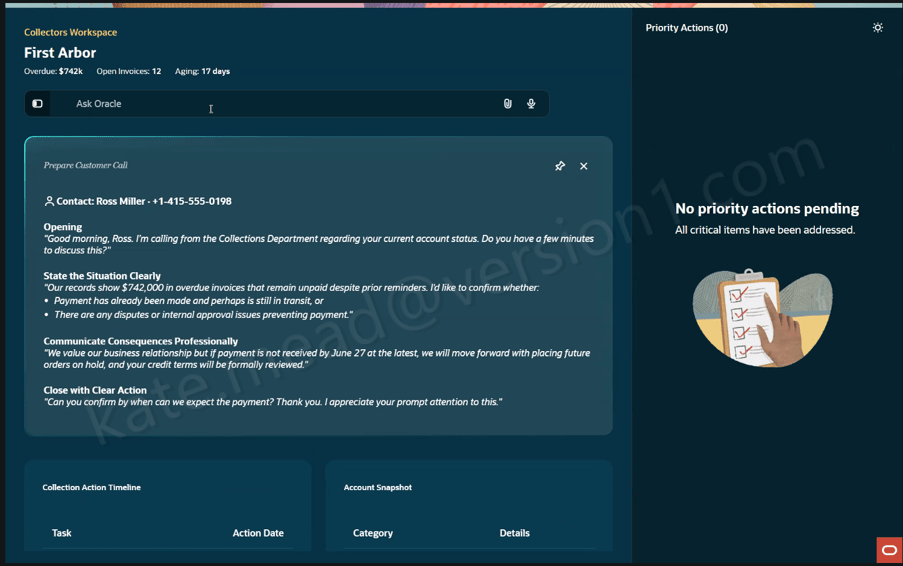
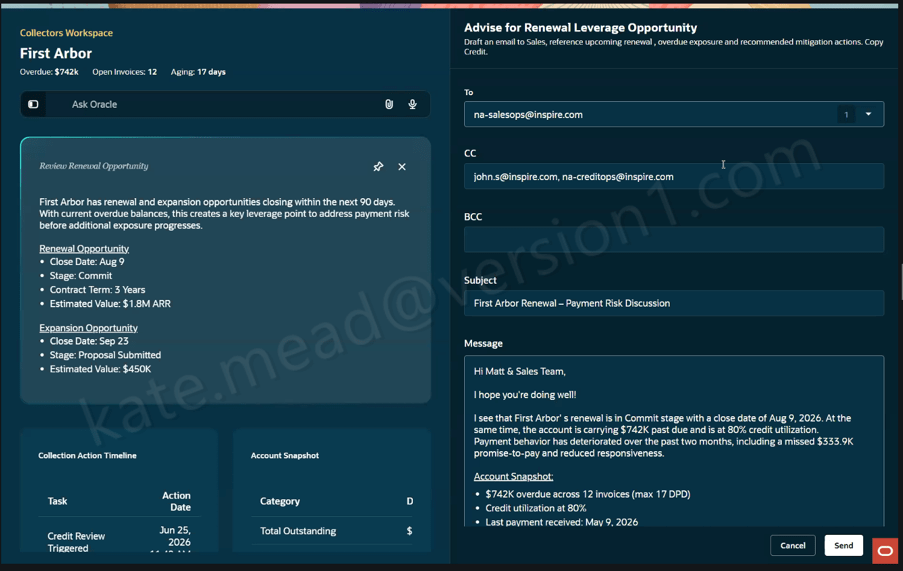
Another example is the Collectors Workspace within ERP. Collections teams often spend considerable time gathering information from different sources before they can determine the appropriate next action. The Collectors Workspace brings together customer history, disputes, payment behaviour and other relevant information into a single view, helping teams focus their attention where it will have the greatest impact.
In both examples, the goal isn’t to replace experienced employees. It’s to remove the effort associated with collecting and organising information, allowing people to spend more time making informed decisions.
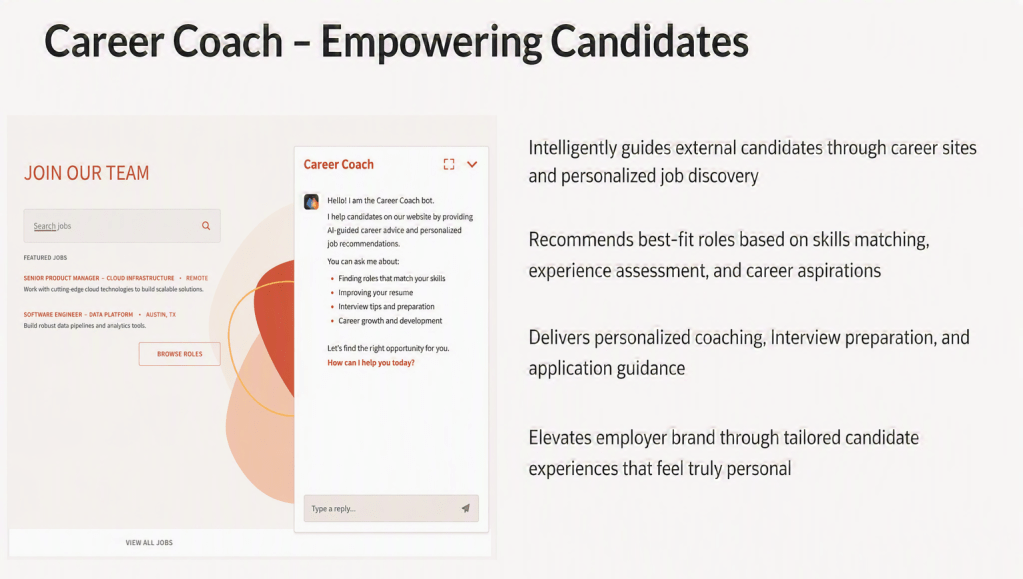
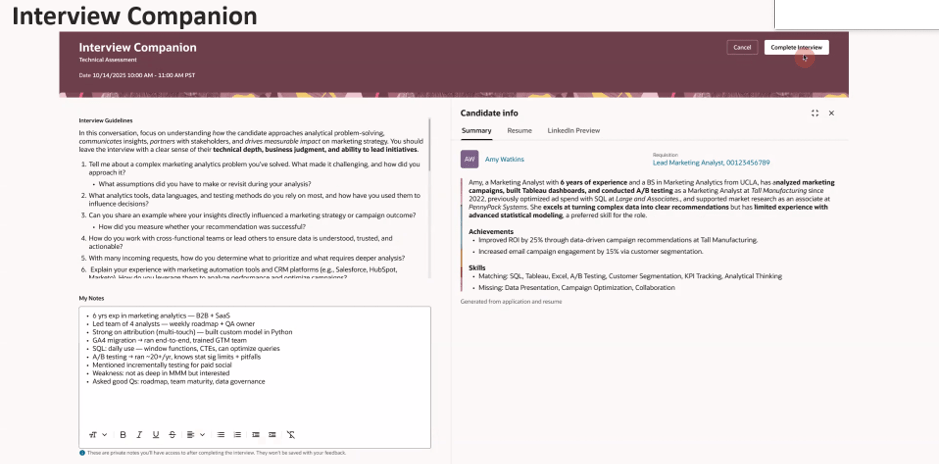
Oracle has continued to expand its HCM agentic application portfolio, with workspaces covering areas such as hiring, career development, workforce operations, employee support and team management. Despite the variety of use cases, a common theme runs throughout them all.
The applications take responsibility for gathering information, coordinating activities and surfacing recommendations, while people remain responsible for decisions that require judgement, experience and empathy. That balance is important because successful AI adoption isn’t about removing human involvement. It’s about enabling people to focus on higher-value work.
The most interesting aspect of Oracle’s Agentic Applications isn’t any individual workspace or feature. It’s the direction of travel. For years, organisations have invested heavily in putting consistent processes and accurate data into their enterprise systems. Agentic Applications represent Oracle’s next step, using that foundation to actively help organisations achieve business outcomes rather than simply record activity. Not every organisation will adopt these capabilities at the same pace, and governance, security and change management will remain critical considerations.
However, the conversation is already changing. Instead of asking how technology can automate individual tasks, organisations can start asking how it can help deliver broader business objectives. That is a much bigger shift than simply adding another AI feature to an application.
If you’re exploring Oracle’s AI strategy, my recommendation is to start small. Identify a business process where information gathering and routine coordination consume significant time, evaluate one of the pre-built agentic applications, and measure the results. The new Agent ROI Dashboard gives organisations a practical way to begin that journey using real data rather than assumptions.
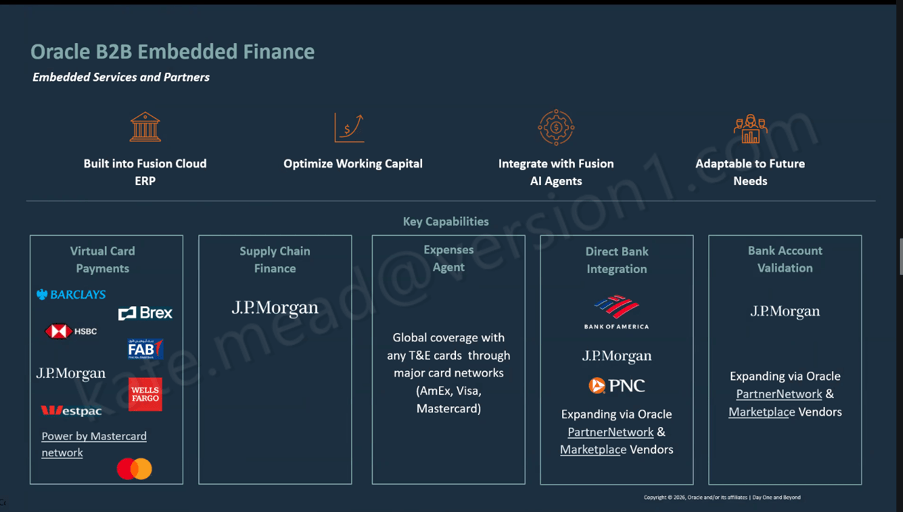
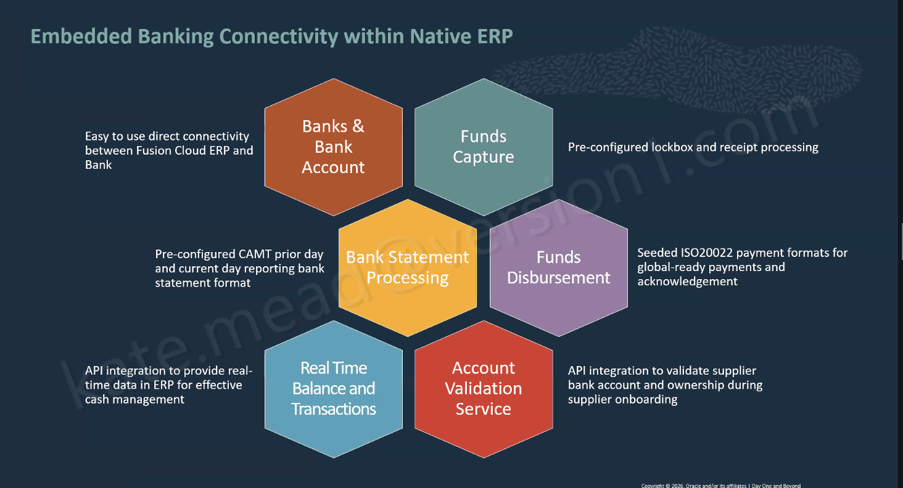
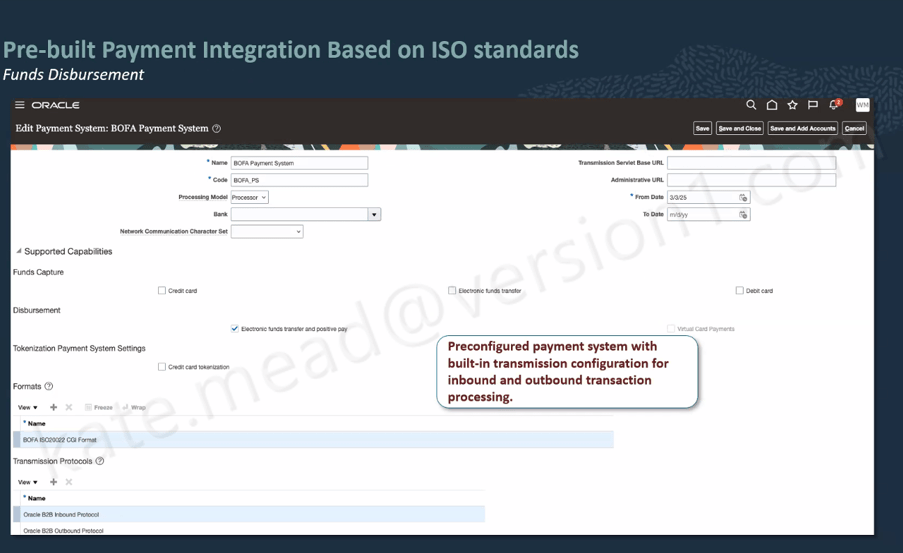
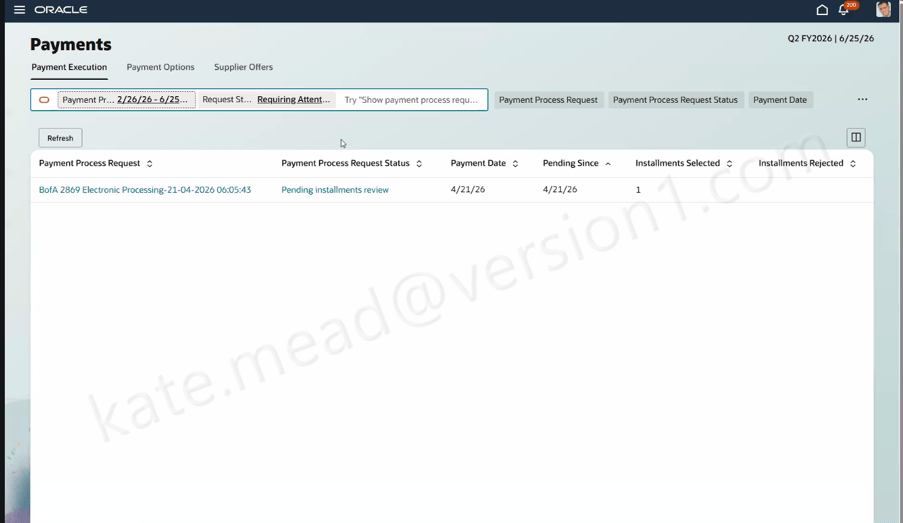
Please note all screenshots are the property of Oracle and are used according to their Copyright Guidelines